Music Catalogue Management Software
If you are looking for catalogue management software for music companies, two options are presented first, one free and one commercial.
Below is the part about choosing the right solution.
DMP
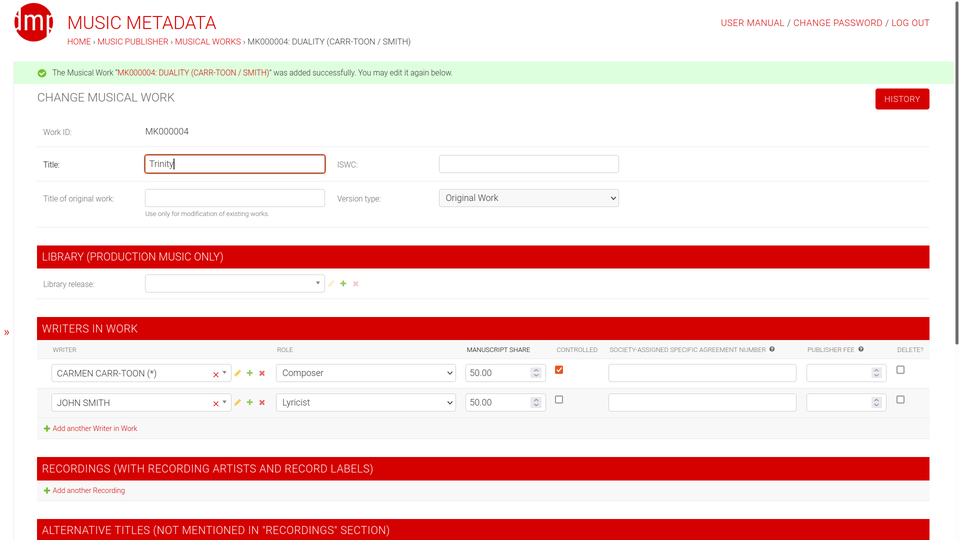 Work editing in DMP: Simple work, two writers, one controlled, one not
Work editing in DMP: Simple work, two writers, one controlled, one not
DMP (Django-Music-Publisher) is free, open-source software for managing music metadata:
- musical works and recordings (with audio files),
- writers, artists and labels (with photos/logos),
- releases/albums (with cover art), and
- music libraries.
It implements CWR protocol for batch registration of musical works with Collective Management Organizations (CMOs) and Digital Service Providers (DSPs).
Simple powerful royalty management can split received royalties among writers and calculate fees.
Compared to the commercial solution, presented below, it has several limitations. Most notably, DMP supports only a single publishing entity, and uses single manuscript share model.
It comes with great documentation and is featured in many of our videos and articles. We offer no individual support for DMP. Bug reports and feature requests can be sent through the code repository.
Project home page: https://dmp.matijakolaric.com
That Green Thing
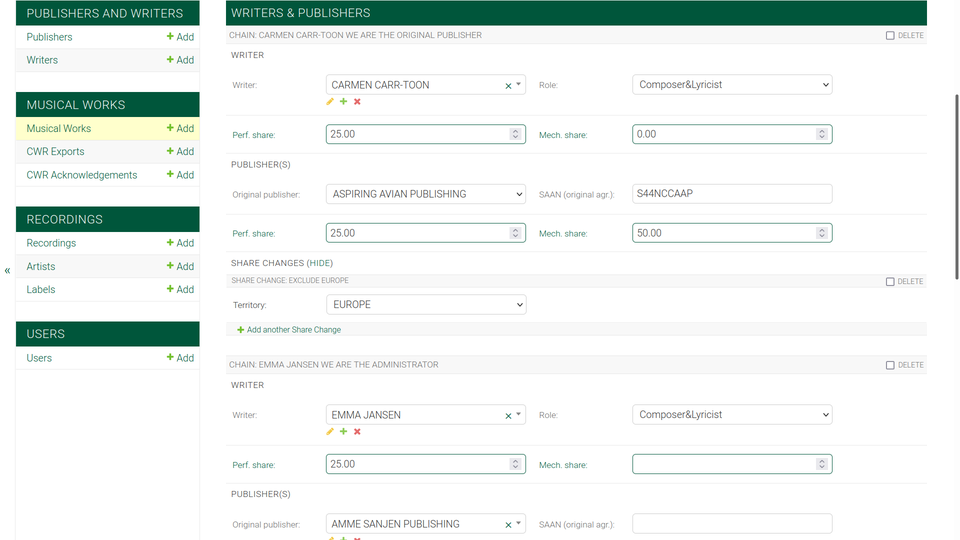 Work editing in That Green Thing, section Writers & Publishers, one writer controlled as original publisher, the other as administrator
Work editing in That Green Thing, section Writers & Publishers, one writer controlled as original publisher, the other as administrator
That Green Thing is DMP's large commercial sibling. Available as software-as-a-service, on top of DMP, it features:
- multiple publishers (controlled and others)
- multiple CMO affiliations for publishers
- administration
- sub-publishing
It comes with great user support, by people who know both the tech and music industry rules and protocols, including specifics for over 20 countries.
Product page: https://thatgreenthing.eu
How to choose the right catalogue management software?
We believe that we offer the best solution for the vast majority of music publishers, as well as most publishers who are also labels. However, while designing our solutions, we carefully considered some trade-offs. And we are completely open about them.
Not everyone is. And there is no reason to trust us either. So, below is the list of articles that might help you in making the right choice.